总结一下最近看的一篇论文,Non-local Neural Networks,一种注意力机制模块,文章相对来说比较老,CVPR2018, 部分内容参考了这篇知乎博客
我将从以下几个方面总结一下论文,也有一点自己的整理,欢迎拍砖。
为什么提出Non-local?
计算机视觉领域,尤其对于动态视频序列中,帧内帧间的依赖关系十分重要。尤其像下图中视频的行为分类任务,全局内容的理解以及不同帧间的联系对于分类结果导向作用很强。现在比较通用普遍的做法是,通过循环卷积网络联系$t$和$t-1$,或者通过更深的网络增大感受野提高对全局内容的理解。尽管如此,这种方式仍旧是比较local的,不论时间方向或者空间位置。而且,最大的问题是:没法进行远距离信息的来回传递;而且deeper网络计算量大但效率低,梯度优化起来也比较困难。
因此,针对远距离信息传递问题,提高长距离依赖,本文从传统的非局部均值滤波方法中受到启发,提出了卷积网络中的non-local,即:某一像素点处的响应是其他所有点处的特征权重和,将每一个点与其他所有点相关联,实现non-local 思想。
【可见,文章解决的痛点targetable,有意义。而且解决方法也有图像处理基础,禁得起推敲】
Non-local 的思想和简单数学原理
Non-local的核心思想就是上面说的,某一像素点处的响应是其他所有点处的特征权重和。因此,假设对于一个2D的7*7特征图,总共是49*1(拉平操作)个位置,每个位置都与其他位置(包括本身位置)有关联性度量,就会得到49*49的关联性矩阵,而这个关联性矩阵经过归一化后其实可以理解为彼此之间的关联权重,因为不同像素点间的关联性都是不同的,因此这个权重本质上其实已经实现了注意力。当将这个49*49的权重再与原特征图49*1做矩阵乘时,得到的49*1矩阵就是该2D特征图所有像素点的响应。因此在这里的2D特征图的空间位置的注意力操作就是这个non-local操作。
以上是举了一个例子,根据核心思想去理解这个东西。下面可以看一下具体的数学公式代入,抽象化。以下是我整理的公式图片,所有公式都在这上面。
将non-local的核心思想某一像素点处的响应是其他所有点处的特征权重和进行数学化,就是图片中的左公式(1),很好理解,其中$y_i$代表第$i$像素点处的响应,$f(x_i, x_j)$表示两个像素点的关联性度量函数,$g(x_j)$表示对$x_j$特征的embedding线性映射,这里用$W_g x_j$表示,$C(x)$表示一个归一化操作。如果左式理解不清,可以看右式,非常直观。
其他所有点$x_j$,权重$f(x_i, x_j)$,特征$W_g x_j$, 和$\sum$, 以及归一化$C(x)$,一目了然。
而在核心思想的数学化公式中,$f(x_i, x_j)$和$C(x)$没有具体的函数定义,下面就对其进行实例化。
- 公式(2)是其中一种常用的高斯函数进行相似度度量,两向量直接进行矩阵乘然后通过指数放大差异;这里归一化函数选用该点处所有相似度值的和$\sum_j f(x_i, x_j)$。这里值得注意的是,归一化函数的选用使得公式(1)变成了$softmax= \frac{\exp(x_i) }{ \sum_j \exp(x_j)}$函数形式;
- 公式(3)是公式(2)的改进形式,先将两向量分别映射到不同的嵌入空间(也就是进行不同的特征线性映射),然后进行公式(2)的应用;
- 公式(4)又是公式(3)的改进形式,不再用指数变换,归一化函数$C(x)$也直接采用$N$;这里主要是为了进行验证$softmax$激活函数的作用;
- 公式(5)是根据Relation~Networks论文提出来的特征concatenate形式;然后进行卷积变换;在卷积中实现不同位置的关联,也就是相似度的度量。
【总而言之,几种相似度度量函数都有基础依据,又有自己实验的想法在里面。数学原理很清晰。】
Non-local在神经网络中的实现
数学原理讲完了,下面就是具体的卷积网络中的应用了。论文以视频流的行为分类做了一个例子,不仅包含了同一帧的空间位置的相似度度量,还有不同帧之间同一位置、不同位置的相似度度量。为了简化,下面主要以图像领域空间位置的相似度度量做一个通俗的解释。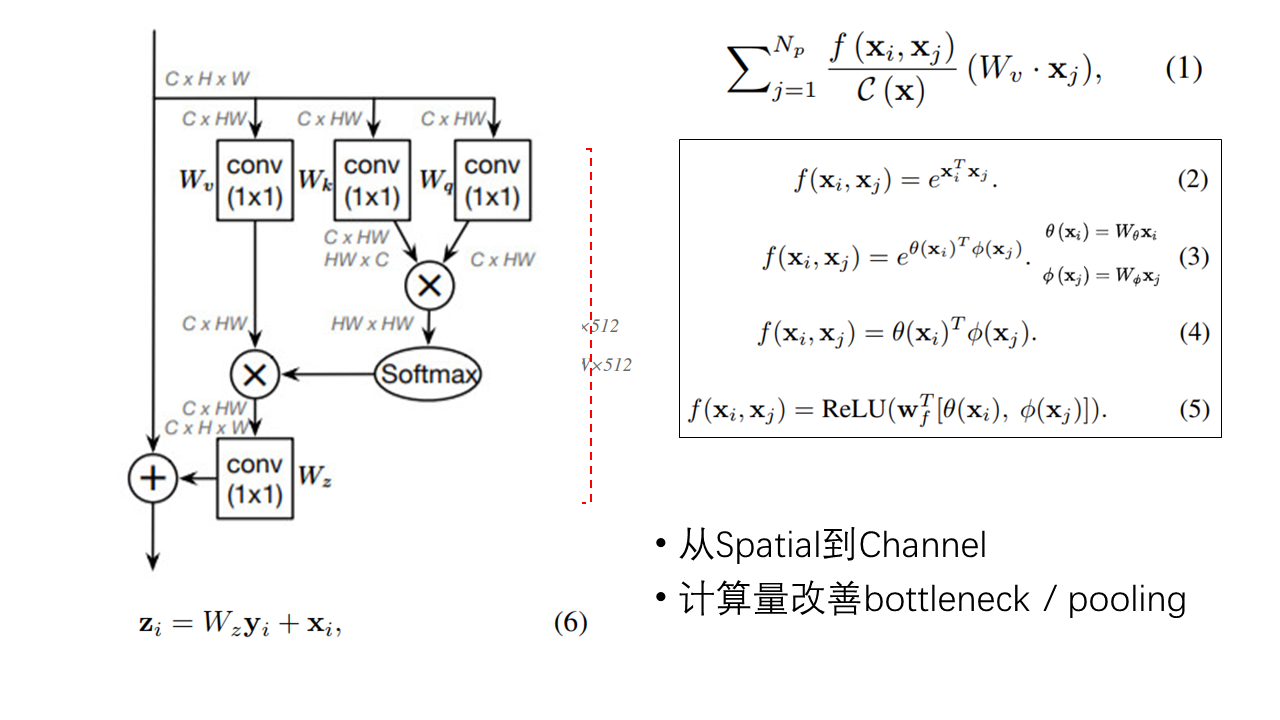
从图片右边公式(3)出发,为了在卷积网络中实现该相似度度量函数下的像素点响应,设计的non-local block具体如图左边网络结构。
从上往下看,输入特征图为$C*H*W$,首先矩阵拉成向量得到$C*HW$,然后采用1*1卷积操作分别进行$g(x)$、$\theta(x)$和$\phi(x_j)$的线性映射,也就是图中的$W_v$、$W_k$和$W_q$;都得到嵌入空间下的$C*HW$;对于$\theta(x)$的$C*HW$进行转置得到$HW*C$与$\phi(x_j)$下的$C*HW$矩阵乘得到$HW*HW$相似度矩阵;然后$g(x)$的$C*HW$与经过$softmax$操作的$HW*HW$相似度矩阵再矩阵乘得到$C*HW$的响应,此时再转换为$C*H*W$即是经过了non-local加强距离依赖的特征图。
论文同时又借鉴了resnet的恒等映射思想,再次对$y_i$下的的$C*H*W$经过1*1卷积然后与原输入特征图进行像素点的加和。
即公式(6)。
理解了公式(3)的这个block结构,剩下的也很好理解。公式(2)的block结构相较于结构图不进行$W_k$和$W_q$的1*1卷积操作;公式(4)相较于结构图不进行$softmax$激活,直接$1/N$归一化即可;公式(5)变换相较于结构图复杂一点,用特征concatenate,然后1*1卷积再进行$ReLU$激活。
其实可以看到,$HW*HW$的相似度矩阵可以是$C*C$;那这时候其实就是通道的关联性度量了。
另外,可以想象的是,像素点关联矩阵的计算量是很大的,因此,为了减少计算量,论文有几个小技巧,一个是通道减半bottleneck操作,另一个是进行尺寸pooling降维。后面还有针对这个弊端提出的几篇论文,CCNet,GCNet等。
【看得出来,在卷积网络中应用也不是很复杂】
论文中的实验部分结果
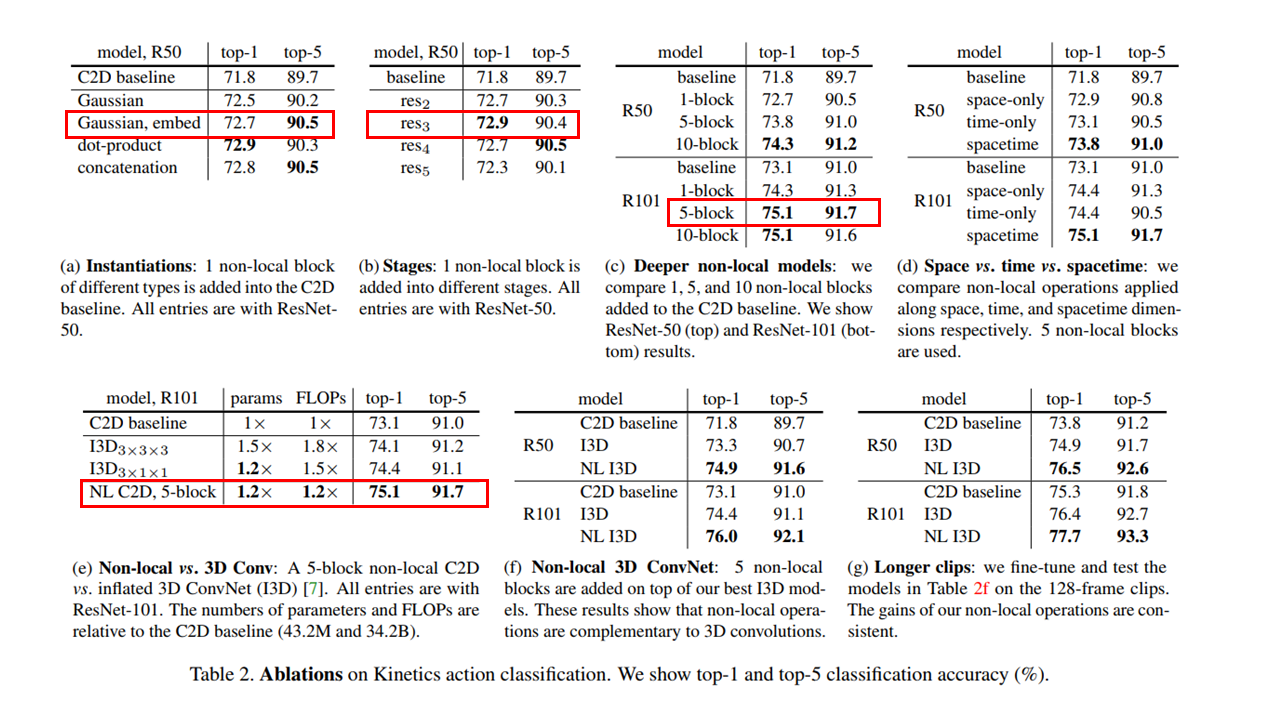
实验部分比较足,主要是通过对比实验,如果想要用non-local block的话可以有所帮助,避免踩坑。
- 第一个,四个相似度度量函数,哪个好?解释是,四个结果都差不多,说明主要是我们这个non-local的思想好,什么度量函数,什么激活函数,不是根本因素。
- 第二个,放在哪里合适? 结果显示,建议放在前面层,后面的层特征图中的空间信息被弱化,所以效果不如前面的好。
- 第三个,几个non-local block合适? 多了好一点,但是多了计算量太大了,trade-off下就5个吧。
- 第四个,针对视频分类中的时间还是空间还是时空的注意力,三种对比实验。不解释
- 第五个,针对baseline的改进,用了non-local,参数量差不多情况下,性能好。
- 后面的不解释了,主要是针对baseline的改进
个人扩展
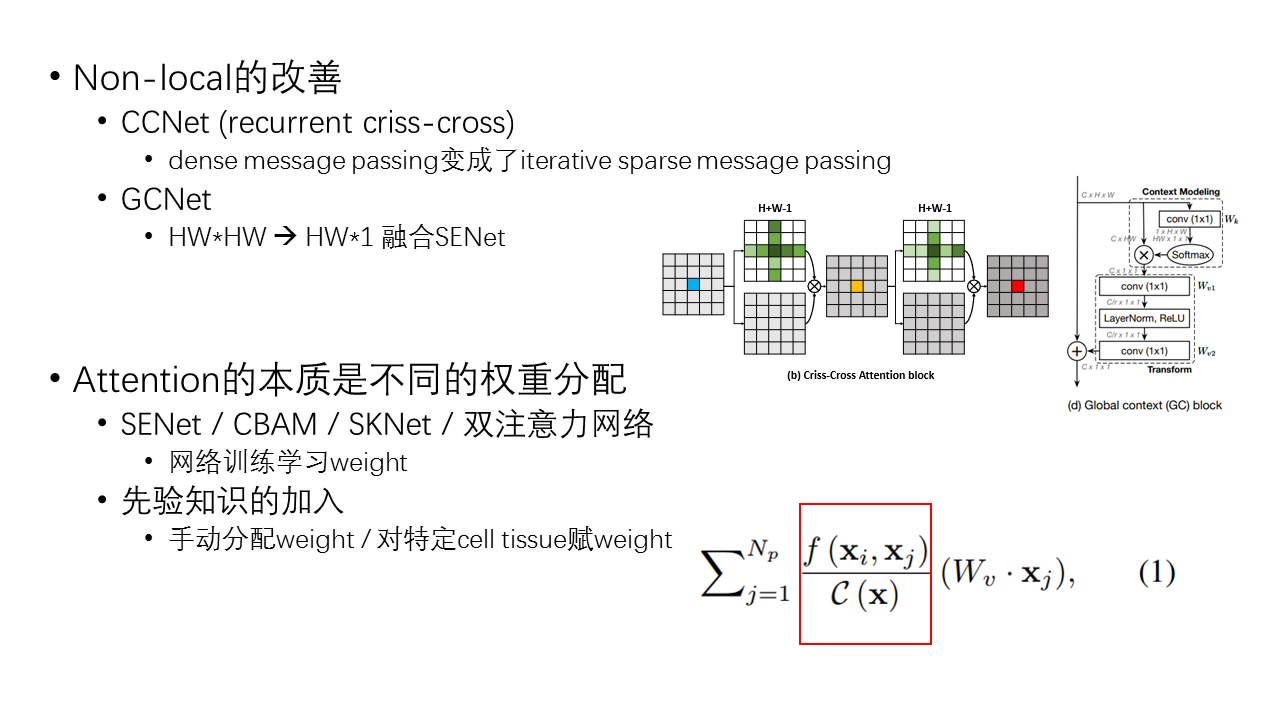
Non-local其实可以被认为是channel level和spatial level的泛化。这种方式通过注意力加强距离依赖,更是直接实现了全局的联系性。既有attention的思想也有context联系的思想。
基于这个non-local,后面相继又有几个网络结构提出来,本质还是做注意力机制,只不过操作不一样,或者是改进版的。像刚刚说的,CCNet, GCNet。可以看图。
另外,想说一点注意力的见解
形如resnet alexnet等通用网络结构中,我们可以理解为空间或者通道间的所有位置,其重要性均等,即权重都为1。而注意力机制的根本目的,就是对原本平均分配的权重通过手动或者自学习的方式进行非等份分配。所以,从这个角度看,挂在嘴边的先验知识或是上下文关系(local, global, context)都可以理解为对原本等价权重的非等分配。在诸如SENet,CBAM中,通过网络训练的方式得到权重;而人为先验,是不是就是手动的权重分配,针对我们觉得重要的部分进行高权重赋值然后操作?
附录
- channel level, SENet SKNet 博客
- spatial & channel level:BAM和CBAM github代码 双注意网络 博客
- CCNet; 理解为对non-local的效率上的改善;由dense message passing变成了iterative sparse message passing。博客
- 网易cs231n课程关于attention的部分