引言
本文记录一下用caffe-segnet训练的过程。虽然现在结果还没出来,但是我已经预感得差不多了,是的,结果不是很好… (写在测试时,结果还ok啊!)
注意:在segnet分割网络中, 注意你的mask一定是uint8型,(0,255)值中的0代表第一类,1代表第二类,2代表第三类…等等。 而不能用logical二值,是会出问题的!
前期准备
- 根据自己的cudnn版本确定安装好caffe-segnet版本
- 到github上下载SegNet-Tutorial文件
- 自己数据集,以
train和test以及train_mask,test_mask形式存放于对应文件夹(我这里是自己做的数据集,搞了一周才把前列腺穿刺数据中的腺体画出来取块并做好了mask)
参考链接
第一步,制作数据集
这一部分基本没有什么干货,主要就是谈一下心路历程。其实搞大数据啊深度学习计算这些,有两种路子,一个是算法开发模型设计,这时候对基础要求高,需要自己设计网络设计算法等等,但是对数据集要求不高,只要拿通用的数据集测试算法性能即可;另一个路子就是拿自己的数据集在别人先进的算法上做,也就是走的应用路线;这时候,自己能根据自己项目的需求、问题,选择合适的算法并制作筛选合适的数据集就相当重要。其实,这个时候,数据集怎么做,做得怎么样,就至关重要了,因为基本上先进的算法都是经过在通用数据集上评估的。anyway, 不管走什么路线,都是要付出心血去做的。不然搞什么都不行。
好吧好吧,跑偏了。说一下,训练和测试数据做好之后,需要做一个train.txt和test.txt甚至val.txt,这个就不多说了,主要就是要保证在训练时网络能寻找到对应每张图像的mask。 因为原图和mask是在不同文件夹的。
另外我有个个人建议,每张图mask的名称和原图保持一致,只仅仅多个_mask后缀。如:15019_1_1.png和15019_1_1_mask.png。
有一点需要注意是,在matlab中保存二值logical图像数据只能以png格式保存
第二步,更改prototxt文件
首先更改segnet_train.prototxt和segnet_inference.prototxt中的source:后面的train.txt及test.txt文件位置,改为自己的存放位置;
然后更改这两个文件中最后位置的num_output=11为自己的类别,如num_output=2,其中11和2表示了自己的分割类别;同时更改segnet_train.prototxt中的ignore_label=11为2,ignore_label=2下方的class_weighting在第三步有讲解;
再然后,更改两个文件中的upsample_w和upsample_h为自己训练图片的尺寸对应的当时大小;如我的训练图像为200x200,而例程是480x360, 所以需要将原来的30,23改为13,13,原来的60,45改为25,25。两个文件中都有需要改的地方,总共是2x2x2个位置需要修改,注意这里一定要改的;
最后,修改segnet_solver.prototxt的net位置和snapshot_prefix位置,可自行参考注释,不再赘言;包括是采用gpu还是cpu跑网络,都可以在这里更改。
第三步,更改class_weighting值
在segnet_train.prototxt文件中,拉到最后,会有形如class_weighting的11个值,表示了所有类别各自占比;可以按如下代码计算自己数据集中不同类别的比重,并更改其中的值,其他的可以注释掉。
第四步,开始训练
在开始训练前,如果希望很快收敛,可以采用ImageNet训练的VGG模型参数来初始化segnet模型参数,下载放到SegNet/Models/下:
VGG_ILSVRC_16_layers模型参数
以上最后一段加上了重定向输出log文件到Log文件夹下
最后,测试结果
打开/Scripts/compute_bn_statistics.py和/Scripts/test_segmentation_camvid.py,更改caffe安装目录;
运行如下,记得更改为自己的caffemodel,/Inference/用于保存计算到的均值和方差数据的文件夹:
打开/Scripts/test_segmentation_camvid.py文件,更改11为自己的类别数量,然后可以选择将label_colours的颜色值更改为自己喜欢的颜色。即可。
运行如下,将iter后面的数字改成自己测试集的数据数量即可:
可以看到预测结果了~~
后面可以再根据需求,保存预测分割结果或者怎么样,都可以!
可选,画出loss曲线
将caffe安装目录下的tools/extra/下的parse_log.sh和extra_seconds.py以及plot_training_log.py.example复制到Log/文件夹下,然后./plot_training_log.py.example 6 loss.png result.log可以看到loss和迭代期的曲线图:如图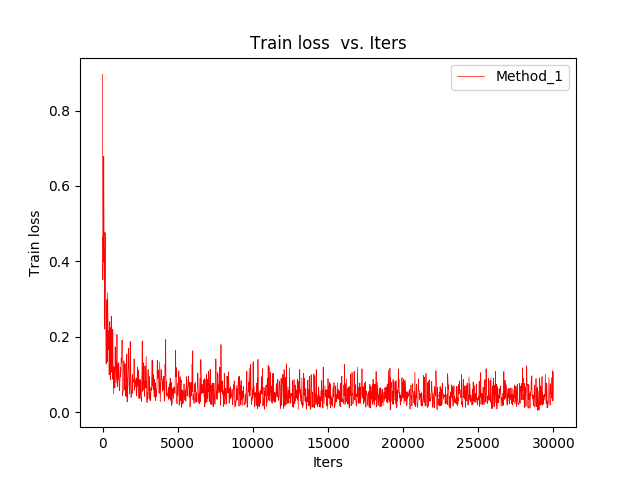
总结
希望以后自己能独立一点,稳重一点。不要被'恶势力'牵住头脑。