引言
这几天玩这个以太妖怪玩得上瘾,先是爬神兽数据,看看神兽图片,看看神兽归属,心里还是挺骄傲的。然后发现查看神兽不需要登陆就能查看,静态网页;但是妖怪信息就必须登陆,动态。所以这几天,工作时间赶工赶点,试着用先前的思路尝试爬取动态网页,抱着试试看的态度结果没想到一上午成功解决问题。特此公告。喜大普奔。
如何查看请求发送地址
打开登陆页面,然后按F12查看控制台,选择Network选项,这时在网页点击登陆,查看控制台变化,这时候应该name下会新增几条记录,通过查看这几个name记录查看登陆和验证码的请求地址。具体可查看下图: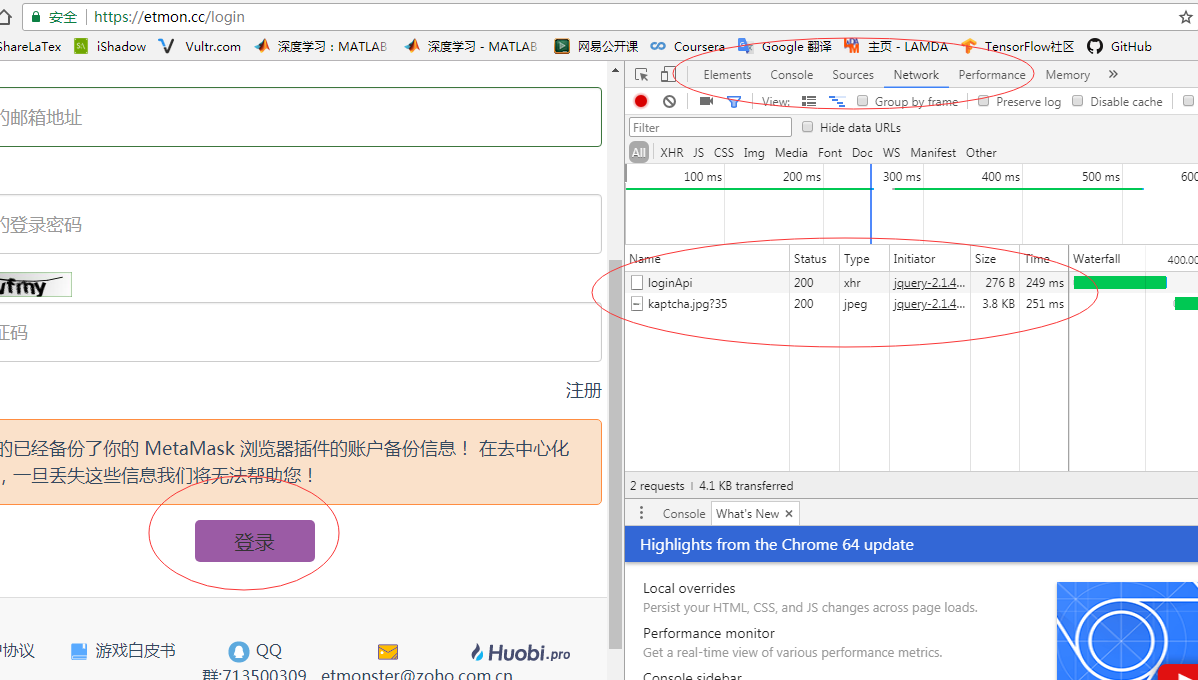
源码共享
以下是源码信息,和之前那篇爬取神兽的post不一样的部分主要在动态网页模拟登陆。要用代码将登陆请求模拟发送出去。更详细可以通过代码理解。。
这次网站内容没有屏蔽,如感兴趣可以尝试。
技术是无罪的,本人单纯性地分享源码,如果对网站造成任何损失,本人概不负责。
结语
- 模拟登陆思路和之前南通大学一键测评脚本代码思路一致,反而更简单了,毕竟只是爬数据,没有模拟更多请求,如购买 出售等信息。。毕竟随随便便就是0.02个eth的,调试不起啊,万一炸天了 。。。
- 好好学习,用技术创造自己的精神世界,做更好的自己!
参考链接
无。